When building machine learning systems, it’s common to take a model pre-trained on a large dataset and fine-tune it on a smaller target dataset. This allows the model to adapt its learned features to the new data.
However, naively fine-tuning all the model’s parameters can cause overfitting, since the target data is limited.
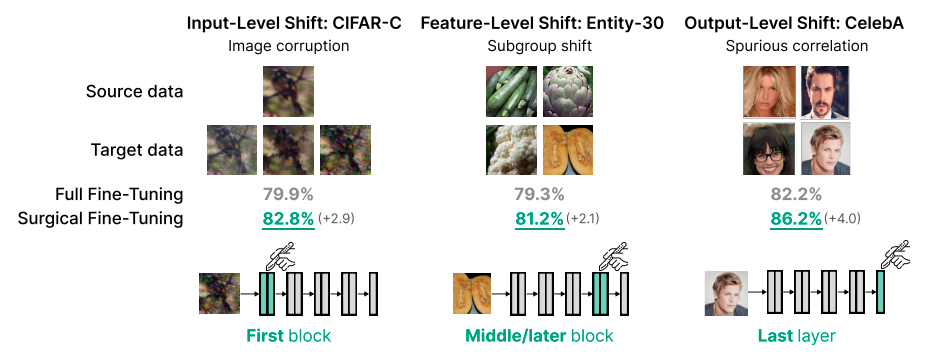
In a new paper, researchers from Stanford explore an intriguing technique they call “surgical fine-tuning” to address this challenge. The key insight is that fine-tuning just a small, contiguous subset of a model’s layers is often sufficient for adapting to a new dataset.
In fact, they show across 7 real-world datasets that surgical fine-tuning can match or even exceed the performance of fine-tuning all layers.
Intriguingly, they find that the optimal set of layers to fine-tune depends systematically on the type of distribution shift between the initial and target datasets.
For example, on image corruptions, which can be seen as an input-level shift, fine-tuning only the first layer performs best.
On the other hand, for shifts between different subpopulations of the same classes, tuning the middle layers is most effective. And for label flips, tuning just the last layer works best.