Source: Model-Agnostic Meta-Learning for Fast Adaptation of Deep Networks
Introduction
In-context learning has emerged as one of the most remarkable capabilities of large language models like GPT-3 and GPT-4. With just a few demonstration examples, these models can rapidly adapt to new tasks and make accurate predictions without any parameter updates. But how does this impressive on-the-fly learning actually work behind the scenes?
In a fascinating new paper from Microsoft Research and Peking University, researchers provide new theoretical insights that help unravel the optimization processes underlying in-context learning in Transformer models. By drawing parallels to gradient descent and analyzing the mechanics of self-attention, they propose viewing in-context learning through the lens of meta-optimization.
This perspective offers a unifying framework for understanding how models like GPT leverage contextual examples to implicitly adapt their behavior in real time. In this post, we’ll break down the key concepts from the paper step-by-step to shed light on the inner workings of in-context learning. Strap in as we demystify how models implicitly optimize themselves given new contextual input – without explicitly updating their parameters!
Bridging In-Context Learning and Gradient Descent
The key insight from the paper is establishing a connection between in-context learning and standard gradient descent optimization. The authors analyze Transformer self-attention under relaxed assumptions to derive an equivalence between attention and computing updates via gradient descent.
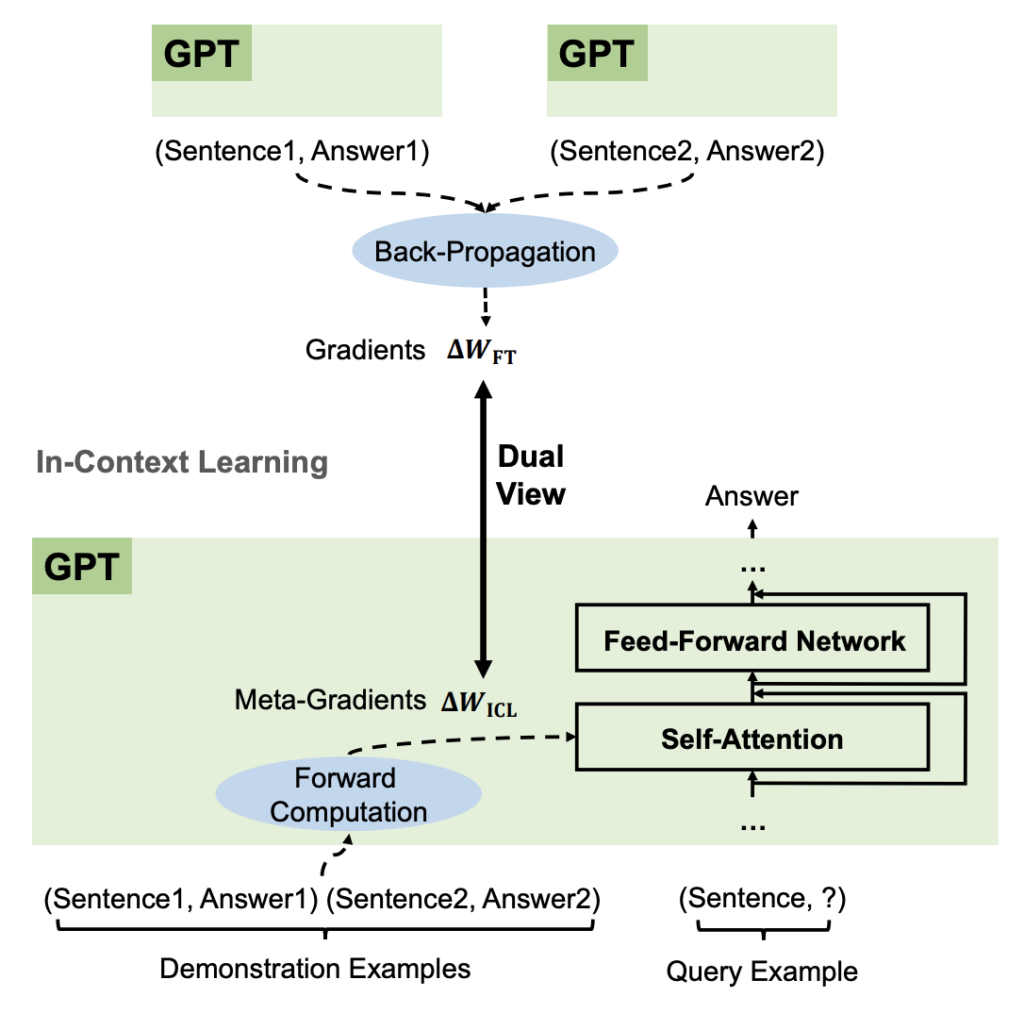
Specifically, they propose viewing the product of the projection matrix of attention values with the input representation of the demonstration/example tokens as analogous to gradients. These “meta-gradients” computed from the contextual examples allow models to rapidly adapt their behavior to new tasks through attention.
“According to the demonstration examples, GPT produces meta-gradients for in-context learning (ICL) through forward computation. ICL works by applying these meta-gradients to the model through attention. The meta-optimization process of ICL shares a dual view with finetuning that explicitly updates the model parameters with back-propagated gradients.”
Meanwhile, the product of the key and value projection matrices with the representation of the original input query tokens (not the demonstration tokens) plays the role of model parameters being updated by the meta-gradients. So while models like GPT keep their parameters fixed during in-context learning, the flows of information facilitated by attention essentially simulate parameter updates.
This understanding of self-attention as an implicit gradient-descent-like optimization process provides a bridge between in-context learning (ICL) and conventional finetuning (FT). The model is “meta-learning” how to optimize itself given new contextual data on-the-fly, without explicitly modifying its weights.
Validating The Meta-Optimization Perspective
The researchers conduct comprehensive experiments to validate their interpretation of in-context learning as meta-optimization. They compare in-context learning to standard finetuning on six NLP datasets and analyze the results from multiple angles.
Remarkably, in-context learning achieves similar performance as finetuning, with comparable accuracy scores across tasks. This suggests in-context learning is successfully optimizing model behavior on par with updating the weights through backpropagation.
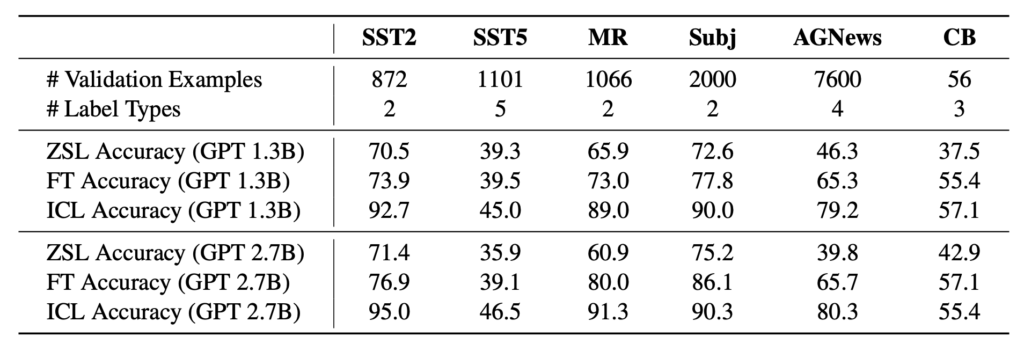
“Statistics of six classification datasets (rows 1–2) and validation accuracy in the zero-shot learning (ZSL), finetuning (FT), and in-context learning (ICL) settings on these datasets (rows 3–8).”
Analyzing model outputs shows in-context learning relies on examples to make correct predictions in almost the same instances as finetuning. The updates to representations also follow similar directions.
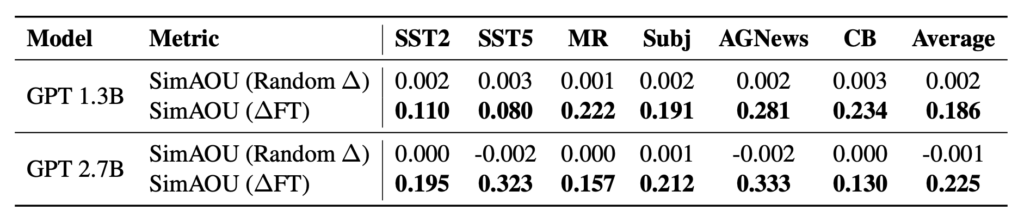
“SimAOU [custom cosine similarity score of ICL and FT attention layer] for two GPT models on six datasets. ICL updates are much more similar to finetuning updates than to random updates. From the perspective of representation, ICL tends to change attention output representations in the same direction as finetuning changes.”
Inspection of the attention distributions further reveals strong parallels — in-context learning mimics finetuning in terms of which input tokens the model focuses most on. Even the relative attention paid to individual training examples matches closely.
“Kendall rank correlation coefficients for two GPT models on six datasets. Compared with random attention weights, ICL attention weights to training tokens are much more similar to finetuning attention weights.”
Overall, the quantitative findings demonstrate that despite not updating parameters, in-context learning produces optimization effects closely mirroring conventional finetuning through gradients. This strongly supports the interpretation of ICL as meta-optimization and implicit parameter updates through attention.
Leveraging The Insights For Model Design
Beyond elucidating the mechanisms of in-context learning, the researchers also demonstrate how these insights can guide innovations in model design.
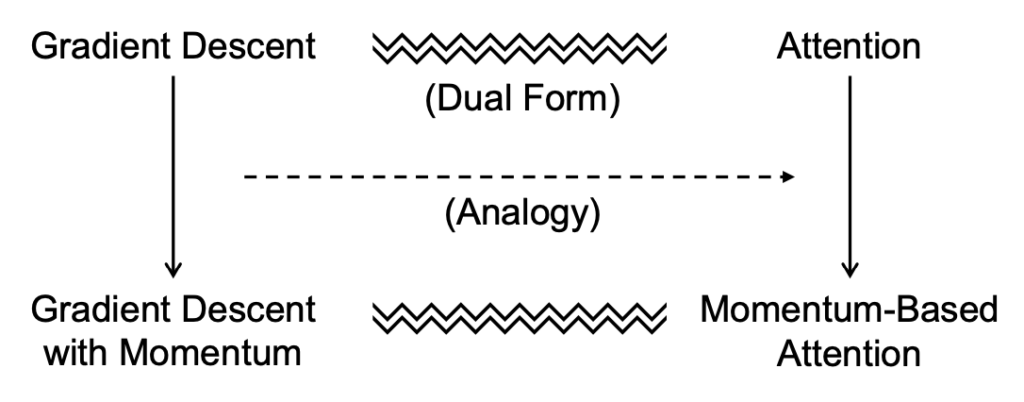
Inspired by the connection to optimization, they propose incorporating momentum into self-attention. Momentum is a popular technique in gradient descent that accumulates historical gradients to stabilize and accelerate convergence of gradient optimization.
“Inspired by the dual form between attention and gradient descent, we introduce the momentum mechanism into Transformer attention by analogy with gradient descent with momentum.”
Similarly, the proposed momentum-based attention aggregates past attention values when computing the current output. This enhances the model’s ability to sustain relevant context throughout a sequence.
Experiments on language modeling and in-context learning tasks show consistent improvements from augmenting attention with momentum. These results provide further validation of the interpretation of attention as propagating meta-gradient-like signals.
The momentum mechanism also gives a blueprint for how the theoretical insights can be translated into practical techniques to improve model capabilities. The parallels to optimization suggest many such opportunities to adapt optimization best practices to attention and in-context learning.
Remaining Questions and Future Directions
While this work provides significant theoretical grounding for in-context learning, some open questions remain to be addressed in future research:
How well does this interpretation generalize beyond Transformer models like GPT to other architectures? The meta-optimization view focuses on self-attention, but other models may implement in-context learning completely differently.
Can we develop a more formal framework to model the hypothesized implicit parameter updates through attention? The current analysis relies on intuitive connections and experimentation. A formal model could enable more rigorous analysis.
Does the conceptualization in terms of optimization fully capture all facets of in-context learning? There may be other important phenomena at play such as generalization that are not encompassed by the meta-optimization perspective.
Can we utilize the parallels to optimization to radically improve in-context learning performance? The momentum mechanism demonstrates initial promise, but more work is needed to translate theoretical insights into substantial capability gains.
While the paper provides a unifying lens for understanding in-context learning, fully unlocking the potential of these models remains an open challenge. However, identifying optimization as a key underlying process guiding in-context learning is an important step toward engineering the next generation of more powerful and capable AI systems.
Thank you for reading!
If you enjoyed this post and would like to stay up to date then please consider following me on Medium.