
Introduction
With the advent of modern deep learning algorithms and architectures, AI has made remarkable progress in the realms of computer vision and language. AI can now process, translate, and generate human-grade images and text. The latest advances are occurring in the realm of language and text, where AI models are inching closer to planning and reasoning.
Of course, by now you’ve probably heard of ChatGPT. ChatGPT is a type of Large Language Model (LLM), and ever since its release, it has taken the world by storm. LLMs are incredibly powerful and can perform a variety of tasks ranging from editing text and correcting grammar, to writing poetry, to assisting in drafting a business plan, just to name a few.
In this post, we’re delving into what LLMs are, as well as their pros, cons, and use cases. It’s important to keep in mind that while very powerful, LLMs are still quite “naive” and have some real drawbacks. They have a long way to go in order to fully reason.
What are LLMs? Foundational Models & Generative AI
LLMs are part of a class of generative AI models known as foundation models. Typically, in AI/ML applications, models are developed and trained in a very task-specific manner. In other words, they are trained on task-specific data to accomplish a predefined task. Consequently, if you have multiple tasks that you want to accomplish, you need to develop multiple models, one for each task.
Foundation models introduce a new paradigm, having been developed to perform multiple tasks and handle various use cases, thus negating the need to develop multiple models for every potential use case. In addition to being able to perform multiple tasks, foundation models can be adapted for new applications, tasks, and use cases. In other words, foundation models can not only execute multiple predefined tasks but they can also be transitioned to any number of new, undefined tasks. This versatility makes LLMs, and foundation models in general, akin to a Swiss Army knife on steroids.
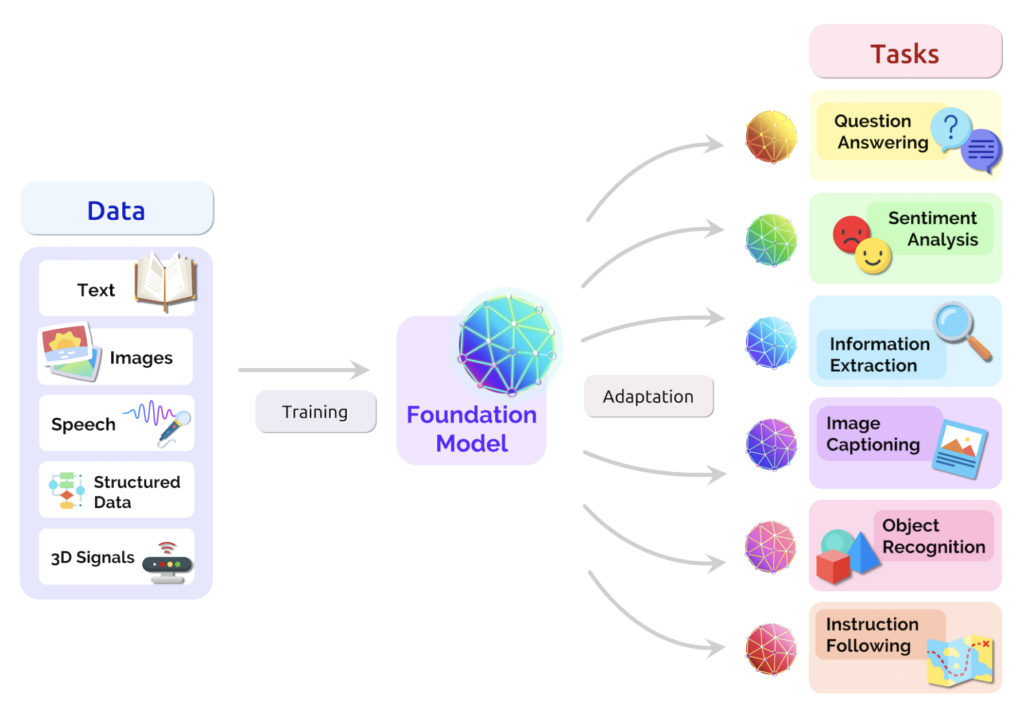
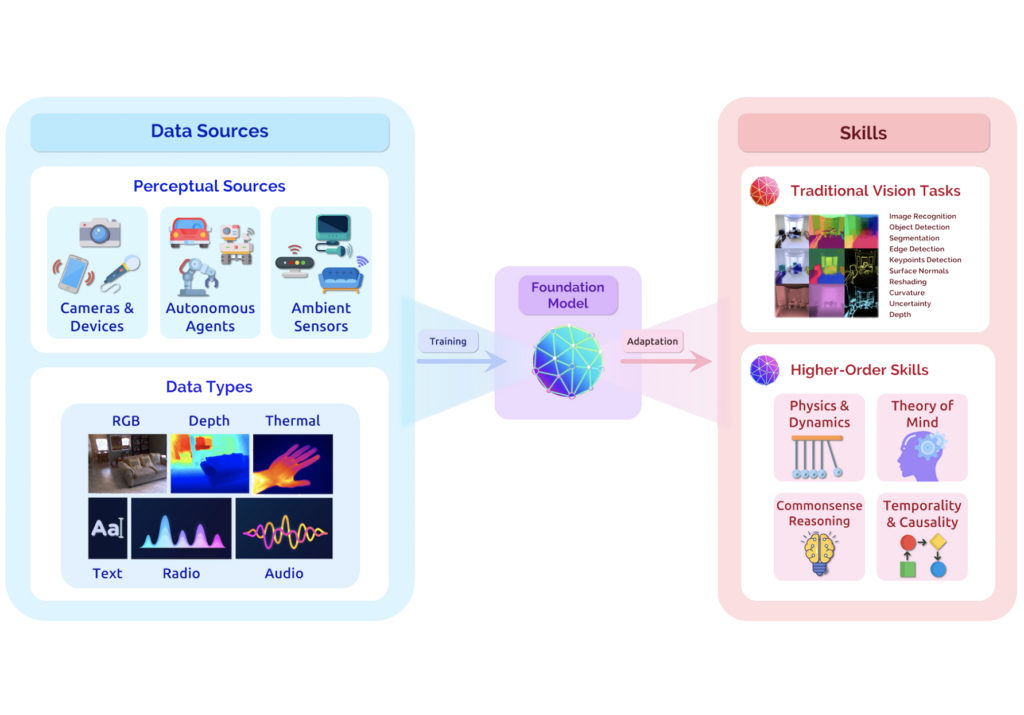
Foundational models appear to be the path forward for achieving artificial general intelligence (AGI). Stanford researchers suggest that, through multi-modal approaches (e.g., incorporating different types of data inputs: text, and image) foundational models may be able to achieve higher-order skills, thus bringing AI closer to the realm of AGI.
What gives foundational models this universal ability to perform multiple tasks?
It’s all in the training and data. In addition to having a “capable” architecture (e.g., a transformer architecture), foundational models are trained on a vast amount of unstructured data, in an unsupervised way (meaning no human intervention is needed to label the data). In the context of LLMs, what this means is that we feed the model massive amounts of text data, specifically sentences, and then we train the model to predict the next word or the last word. This generative capability to predict the next word based on previous words is why foundational models are part of generative AI or called generative AI models.
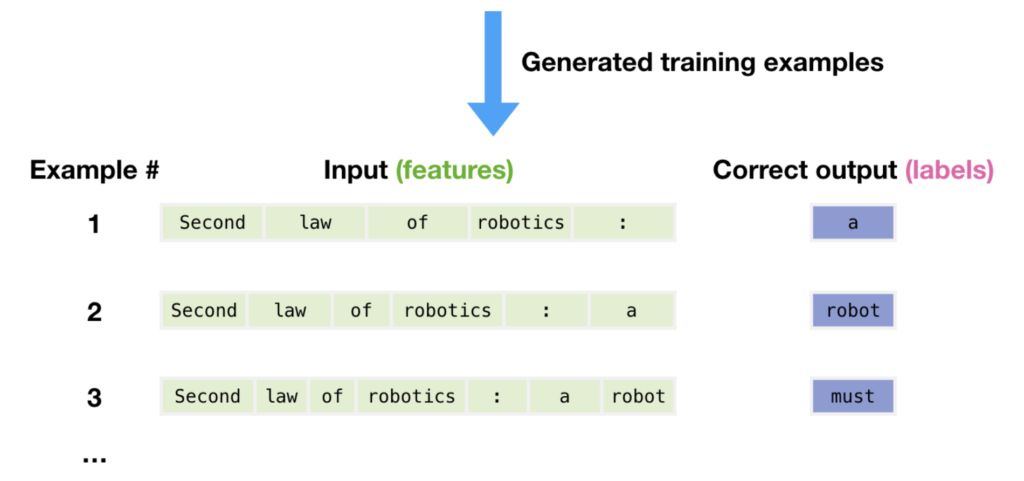
In addition to being generative, what makes these models so versatile is their ability to generalize to other tasks if tweaked. That is, if you give them small amounts of labeled data, you can fine-tune them to perform traditional NLP tasks like classification or named entity recognition (processes not typically associated with generative AI). When you fine-tune a model, you provide small amounts of labeled data that can be used to adjust the (already learned) model parameters to better accomplish a specific task. Even if you don’t have labeled data, or have a very small amount of it, you can still tune the model to perform a specific task. This is because these models work very well in a low-labeled data domain. (You can use prompt engineering to achieve this. For example, provide the model with a sentence and then ask it to classify the sentiment of that sentence. These models work surprisingly well in these new/different domains.)
Foundational models are not only used in the language domain, but also in a variety of other domains, e.g. in vision, chemistry, or healthcare and biotech. For example, given a text prompt, DALLE2 can generate realistic or artistic images to match the request in the prompt. Or generative AI to produce grounded radiology reports or novel protein design modalities.
How to Model Language? A Language Modeling Primer
Language modeling involves predicting words, phrases, and sentences in a way that resembles human communication. One common method is by using frequency tables, which calculate the frequency of queries based on how many people have used them. The aim is to assign a probability to every sentence.
However, the frequency method doesn’t allow for scoring previously unseen sentences. With over 100k words in the English language and more than 10 words in a typical sentence, calculating all possible combinations is impractical. Thus, modeling grammar and style becomes essential.
A basic approach is to treat language as a time series, predicting the next word based on the previous word only. This method, though, can generate nonsensical text. Increasing the window size in the conditional probability can help, but long-range dependencies in a sentence require modeling extensive conditional probabilities, leading to highly complex models.
Instead, function approximation can be utilized. Techniques like Fourier series, Taylor series, and neural networks can approximate almost any function. For language modeling, neural networks are used, and require converting words into numerical representations while maintaining semantic meaning, which can be achieved using word embeddings.
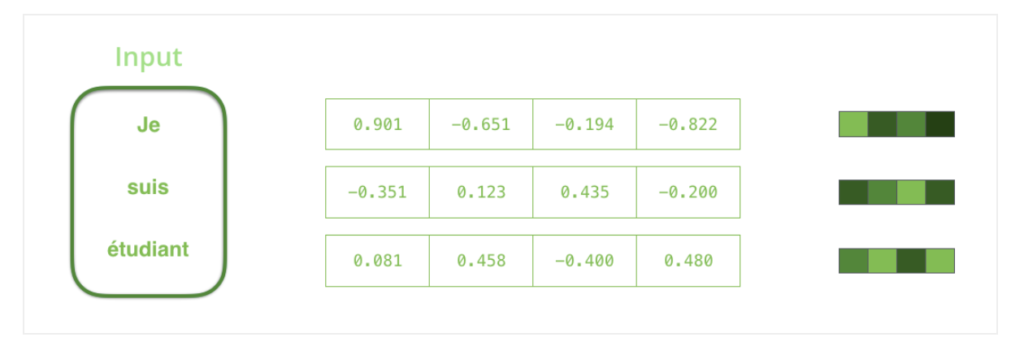
However, brute-force neural networks are insufficient. A method to produce variable-length sequences is needed, as well as a means to focus on the most critical words in a sentence. This can be accomplished through deep learning sequence modalities, and “attention” mechanisms, explained in more detail in the paragraphs that follow.
How LLMs Like ChatGPT Work
Large language models like GPT-4 are sequence models. Sequence models are a type of machine learning model designed to handle input data that comes in the form of sequences, such as time series data or natural language text. In the case of large language models, they process and generate sequences of text, one token at a time.
These models are typically based on deep learning architectures like Recurrent Neural Networks (RNNs), Long Short-Term Memory (LSTM) networks, or Transformer architectures.
RNNs and LSTMs were the first sequence models to emerge, and while they revolutionized deep learning for sequence applications, but suffered significantly from the vanishing/exploding gradient problem (i.e., they have a difficult time understanding and capturing long-range sequence dependencies). Transformers solved this issue, and thus enabled the explosion of powerful sequence-based models.
GPT-4, for example, is based on the Transformer architecture, which uses self-attention mechanisms to process and generate text. Transformers have proven to be highly effective for a wide range of natural language processing tasks, including machine translation, text summarization, and question answering.
Attention
Attention is a mechanism that enables AI/ML models to focus on the most relevant parts of the input data when making predictions. It mimics the human ability to pay selective attention to specific parts of a given input when processing information.
In the context of language models, attention is particularly useful when dealing with sequences of words, such as sentences or paragraphs. It helps the model identify which words are most important or contextually relevant when predicting the next word or generating output.
The attention mechanism works by assigning weights to each word in the input sequence. These weights indicate the significance or contribution of each word to the final output. The model then uses these weights to focus on the most important words, improving its performance on tasks like translation, summarization, and text generation.
The attention mechanism is a key component of the transformer architecture, which has become the foundation for many state-of-the-art language models like GPT-3, BERT, and T5. The attention mechanism, combined with the transformer architecture, allows these models to better capture long-range dependencies and complex relationships within the text.

In the example above, the model correctly identifies “European Economic Area” as the English translation even though the words are reversed in French (“européenne économique zone”). The other words are in a similar order.
Transformers
Models dealing with language must account for word order. Recurrent neural networks (RNNs) process words sequentially, but they struggle with long text sequences and suffer from vanishing/exploding gradient issues, hindering learning long-range dependencies. Additionally, RNNs are not easily parallelizable for training on multiple GPUs.
Transformers revolutionized the field of sequence and language modeling, by enabling the learning of long-range dependencies, and by their ability to be trained in a parallel fashion. There are three key concepts that make transformers work: positional encoding, attention, and self-attention.
Positional encoding assigns a number to a word based on its position in a sentence, storing information about word order within the data. As the model trains on large amounts of text, it learns to interpret these encodings and understand word order importance.
Attention is crucial for tasks like translation. It enables a model to consider every word in the source sentence while translating a word in the output sentence. Attention mechanisms learn the importance of certain words more than others by studying language pairs.
Self-attention is essential for understanding language meaning. Transformers, as they analyze vast amounts of text, develop an internal representation of language, learning rules of grammar, gender, tense, and more. Self-attention helps models understand words in the context of surrounding words.
For instance, the word “server” has different meanings in the following two sentences: “Server, can I have the check?” and “Looks like I just crashed the server.” By examining the context, self-attention helps neural networks disambiguate meanings, recognize parts of speech, and identify word tense. In summary, self-attention provides valuable insights for language understanding.
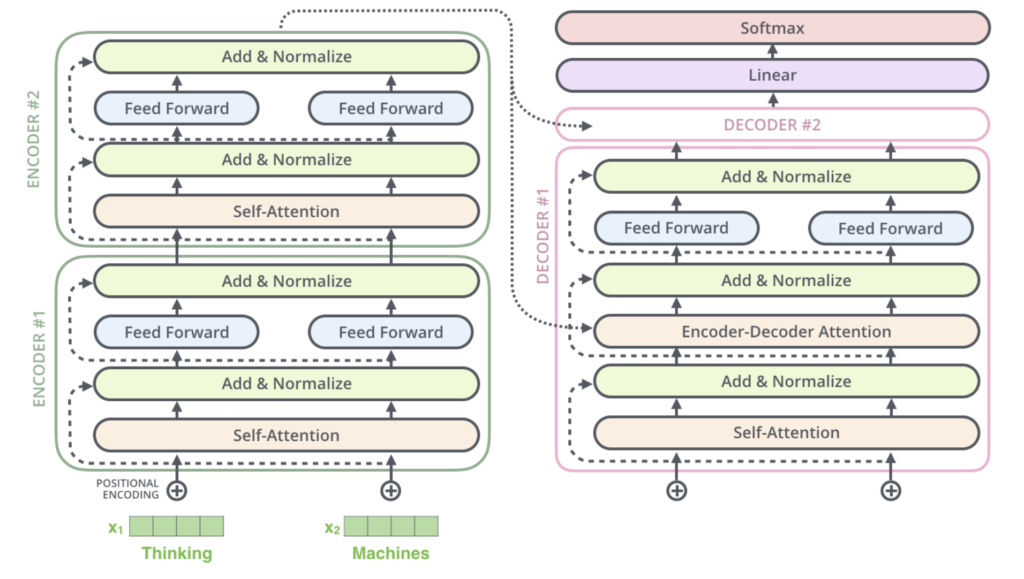
Inside a transformer, encoders and decoders are stacked, each containing self-attention layers and feed-forward neural network layers. The encoder’s inputs pass through the self-attention layer, which allows the encoder to consider other words in the sentence while encoding a specific word. Then, the output of the self-attention layer goes through a feed-forward neural network. The decoder also has both layers, with an added attention layer that focuses on relevant input sentence parts.
In natural language processing (NLP), words are turned into vectors using an embedding algorithm. Each word is embedded into a 512-dimensional vector, which only occurs in the bottom-most encoder. Transformers process words in parallel, with dependencies between paths in the self-attention layer but not in the feed-forward layer.
Self-attention helps the transformer associate words with their relevant context. For example, in the sentence “The animal didn’t cross the street because it was too tired,” self-attention enables the model to associate “it” with “animal.” The self-attention calculation includes creating query, key, and value vectors for each input vector, calculating scores, normalizing scores with a softmax operation, weighting value vectors, and summing them up to generate the output of the self-attention layer.
The transformer architecture further refines the self-attention layer by adding a multi-headed attention mechanism, which enhances the model’s ability to focus on different positions and provides multiple representation subspaces. To condense multiple matrices into a single one, they are concatenated and multiplied by a weight matrix.
To account for word order, the transformer adds position-specific vectors to input embeddings, enabling meaningful distances between vectors during attention calculations. Additionally, each sub-layer in the encoder has a residual connection and layer normalization step.
Decoders work similarly to encoders, but their self-attention layers only attend to earlier positions in the output sequence. The encoder-decoder attention layer in the decoder creates a queries matrix from the layer below and takes key and value matrices from the encoder’s output. The decoder stack’s output is a vector that goes through a final linear layer followed by a softmax layer to generate probabilities for each word in the output vocabulary, and the word with the highest probability is selected as the output.
How ChatGPT Is Trained
ChatGPT is trained through a sequential process involving three main steps: generative pretraining, supervised fine-tuning, and reinforcement learning from human feedback.
Generative Pretraining: ChatGPT is first trained as a raw language model on a large amount of unstructured text data. The model learns to predict the next token in a given sequence, allowing it to grasp the probabilistic dependencies between words, sentences, and paragraphs. However, this step alone is not enough for task-specific requests from users.
Supervised Fine-tuning: The model is further refined using human demonstrations, where human contractors engage in conversations while playing both user and chatbot roles. The resulting dataset helps train the model to imitate ideal chatbot behavior. Despite improvements, the model still faces challenges due to distributional shifts and compounding errors when encountering novel situations.
Reinforcement Learning from Human Feedback: To address these limitations, the model is fine-tuned using reinforcement learning based on human preferences. AI trainers hold conversations with the current model and rank alternative responses. A separate reward model is trained on these rankings and assigns scalar scores to the responses. These scores serve as rewards, allowing for more interactive and robust training.
Using LLMs
In what ways can you use LLMs? Some common applications of LLMs include:
- Text completion and generation: LLMs can complete sentences, and paragraphs, or generate entire articles by predicting contextually relevant text.
- Machine translation: LLMs can translate text between different languages with high accuracy, enabling cross-lingual communication.
- Sentiment analysis: They can analyze the sentiment expressed in text, such as determining if a review is positive, negative, or neutral.
- Text summarization: LLMs can generate concise summaries of long articles, documents, or any text, helping users grasp the main points quickly.
- Question-answering: They can understand questions posed by users and provide relevant, accurate answers by analyzing and extracting information from a given text or their internal knowledge.
- Named entity recognition: LLMs can identify and classify entities within a text, such as people, organizations, locations, dates, and more.
- Text classification and topic modeling: They can categorize and organize text into different classes or topics, facilitating content analysis and organization.
- Grammar and style correction: LLMs can identify and correct grammar, spelling, and style errors in a text, improving the overall quality of writing.
- Conversational agents: They can engage in conversation with users, providing helpful information, guidance, or simply engaging in casual chat.
- Code generation: LLMs can generate programming code based on natural language descriptions of desired functionalities, assisting developers in their work.
For models that are closed source, like ChatGPT, you’ll have to sign up for an account and access the LLM through their web interface (or via an API key if you’re a developer). You can sign up for ChatGPT at chat.openai.com.
However, there are also a ton of open-source options. Thanks to open-source companies like HuggingFace, which curates and houses a plethora of language models, datasets, and developer tools, you can directly integrate or tune an available LLM into your app or for your use case.
Since the release of ChatGPT, there has been a significant effort in open-sourcing LLMs, and as a result, there are now a wide variety of open-source versions of LLMs.
Tuning LLMs
LLMs can be tuned and tailored to tasks specific to your use case (if you have access to the model and its weights, i.e. open-source models). This is done via in-context learning or parameter finetuning.
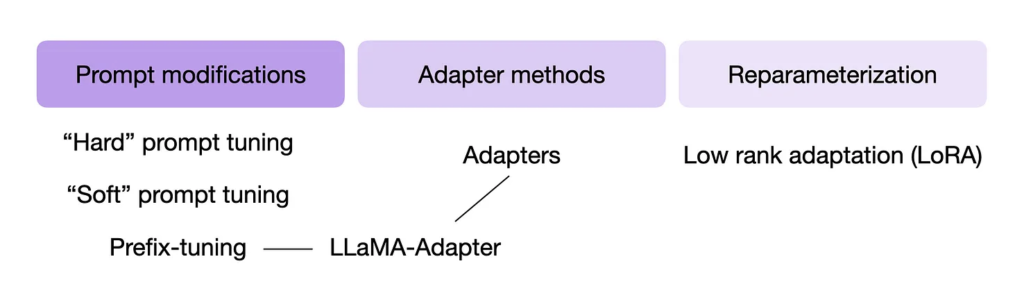
In-context learning, or prompt tuning, refers to providing examples in the input prompt. This enables the LLM to handle new tasks that it wasn’t explicitly trained on, without the need for further training or finetuning.
Prompt tuning is a resource-efficient alternative to parameter finetuning. However, it typically underperforms compared to finetuning, as it doesn’t modify the model’s parameters for a specific task, which could limit adaptability. Furthermore, prompt tuning can be labor-intensive, requiring human involvement to evaluate different prompts.
Another method for in-context learning is indexing. It turns LLMs into information retrieval systems that can extract data from external resources and websites. The indexing module dissects a document or website into smaller pieces, converts them into vectors, and stores them in a vector database. When a user submits a question, the module calculates vector similarities and fetches the top matches to generate the response.
Nonetheless, if access to the LLM is available, adapting and finetuning it on a task using data from a specific domain generally yields better results. There are several ways to do this:
Feature-Based Approach: Load a pretrained LLM and apply it to the target dataset. Generate output embeddings for the training set, which can be used as input features to train a classification model, like logistic regression, random forest, or XGBoost.
Finetuning I — Updating The Output Layers: This approach only trains the newly added output layers, keeping the parameters of the pretrained LLM frozen.
Finetuning II — Updating All Layers: Although finetuning only the output layer can give comparable results to finetuning all layers, the latter almost always gives superior performance. The catch is that it’s more computationally expensive due to the larger number of parameters.
Parameter-efficient finetuning, or PEFT, can be a solution for finetuning more layers while keeping computational and resource footprints low. It has numerous benefits, including reduced computational costs, faster training times, lower hardware requirements, better modeling performance, and less storage need.
For larger models that barely fit into GPU memory, PEFT techniques like prefix tuning, adapters, and low-rank adaptation can be used. These methods involve the introduction of a small number of additional parameters to be finetuned, modifying multiple layers, and often yield better predictive performance at a lower cost.
LLMs Advantages
Large Language Models (LLMs) offer significant advantages in terms of performance and productivity. These models have been trained on vast amounts of data, which allows them to excel when applied to smaller tasks, often outperforming models that have been trained on a limited number of data points. This extensive pre-training enables LLMs to leverage all the unlabeled data they have seen, which can be particularly beneficial when labeled data is scarce. By using appropriate prompting or tuning, it is possible to create a task-specific model with less labeled data, thereby increasing efficiency and reducing the time and resources required for model training.
LLMs are particularly adept at writing and editing content. They can generate coherent and contextually relevant text, making them valuable tools for a variety of applications, from drafting emails to creating content for websites.
LLMs Disadvantages
Despite their advantages, LLMs also have their share of disadvantages. It’s important to note that due to their generative nature, LLMs may hallucinate and occasionally produce factually incorrect information. They can invent non-existent people, places, things, and events, which can be problematic if the generated content is not properly vetted.
Another one of the main challenges with LLMs is the high compute cost associated with training, hosting, and using these models. The sheer size of the datasets used for training these models also raises issues of trust. Since LLMs are trained on large datasets scraped from the internet, it’s impossible to manually sift through all the data to label it or identify instances of false information, hate speech, or biased content. Furthermore, access to the original training data may not always be available, which can complicate efforts to understand and improve the model’s performance.
LLMs also occasionally struggle with common sense issues. While they can generate text that is grammatically correct and contextually relevant, they may not always produce content that aligns with basic common sense or real-world knowledge. This can lead to outputs that, while technically sound, may not make sense in a practical context. Therefore, while LLMs offer significant advantages, their use should be accompanied by a degree of caution and oversight.
How to Use ChatGPT?
ChatGPT excels at generating human-grade (reasonable) text content. If prompted the right way, here are a few things that ChatGPT can do:
- Summarize a news article
- Write a blog post
- Generate code
- Create a YouTube video script
- Create marketing content
- Write lyrics or poetry
- Edit articles
- Act as a virtual assistant
- And the list goes on…
However, as mentioned on their website, ChatGPT “may produce inaccurate information about people, places, or facts.” So, use with caution in this regard.
The more specific you can be with ChatGPT, the better. When giving it instructions, talk to ChatGPT like you’re talking to a human, like you’re instructing a new hire for a job; explain things in detail. Providing specific details and giving examples in your prompts helps improve the performance.
Where do we go from here?
There is still significant room for improvement for LLMs. LLMs have a long way to go in terms of understanding common sense and avoiding hallucination. Some strategies that are already being worked on or are on the horizon include training on more data, better reinforcement learning and human-in-loop methods, and incorporating multimodal data (information from images etc.) and developing multimodal LLMs. Most likely, most of the advances will occur in finetuning LLMs to create domain-specific large language models, like PROTBERT, clinical language models, etc.
AI research is on the verge of shifting its focus from “learning from data” to “learning what data to learn from”. Current state-of-the-art deep learning models, like GPT-[X] and Stable Diffusion, have the capacity to model vast amounts of data. However, the performance of these large models is greatly influenced by the quality of training data. This has led to a growing emphasis on data collection and generation for enhancing model performance.
It has been observed that concentrating on high-quality data during training can significantly improve learning efficiency, resulting in more accurate models at lower computational costs. Additionally, to prevent learning plateaus, models need to continually seek new, informative training data. This highlights the importance of open-ended exploration processes, allowing learning systems to autonomously gather or generate new training data. Consequently, research investment is expected to shift from model design and optimization to the design of exploration objectives and data-generation processes.
The research focus is anticipated to shift toward designing and optimizing processes that generate training data for models. Generative models, like DreamFusion, can serve as world models that are continually updated with real-world data, acting as open-ended data generators. Interestingly, large language models (LLMs) can self-improve by training on their own filtered, high-quality outputs, enabling them to teach themselves how to use new tools, as showcased by Toolformer.
Keeping Track of the Latest LLM Developments
Additionally, the Stanford HELM project curates a leaderboard of foundation models, listing performance metrics for each model for a given task at a given point in time.
References & Additional Resources
- Understanding Large Language Models. A history of the technical foundations and development of LLMs.
- Recent Open Source Models:
– Databricks Dolly
– StabilityAI StableLM - Practical Guide for LLMs with LLM history and literature references
- RNNs (A stepping stone for learning about transformers: prerequisites include neural networks, gradient descent and backprop)
– Recurrent Neural Networks (RNNs), Clearly Explained!!!
– A friendly introduction to Recurrent Neural Networks - LSTMs (A stepping stone for learning about transformers: prerequisites include neural networks, gradient descent and backprop, and RNNs)
– Long Short-Term Memory (LSTM), Clearly Explained - Visualizing A Neural Machine Translation Model (Mechanics of Seq2seq Models With Attention)
- The Illustrated Transformer
- What are Transformer Neural Networks?
- Let’s Build GPT: from scratch, in code, spelled out
- How ChatGPT is Trained
- How to create a private ChatGPT with your own data
- Parameter-efficient tuning methods
