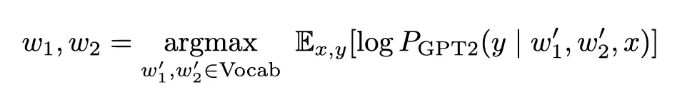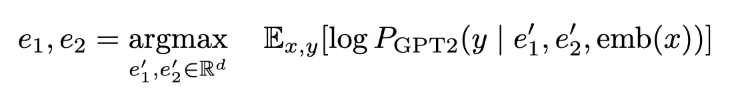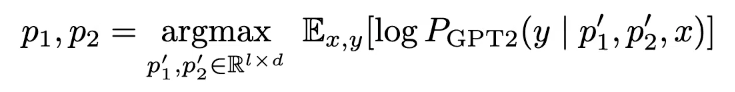Natural language generation (NLG) models like the GPT series have enabled remarkable progress on conditional text generation tasks such as summarization and table-to-text.
However, fine-tuning these large pretrained models on downstream NLG tasks requires updating all model parameters, which is computationally expensive.
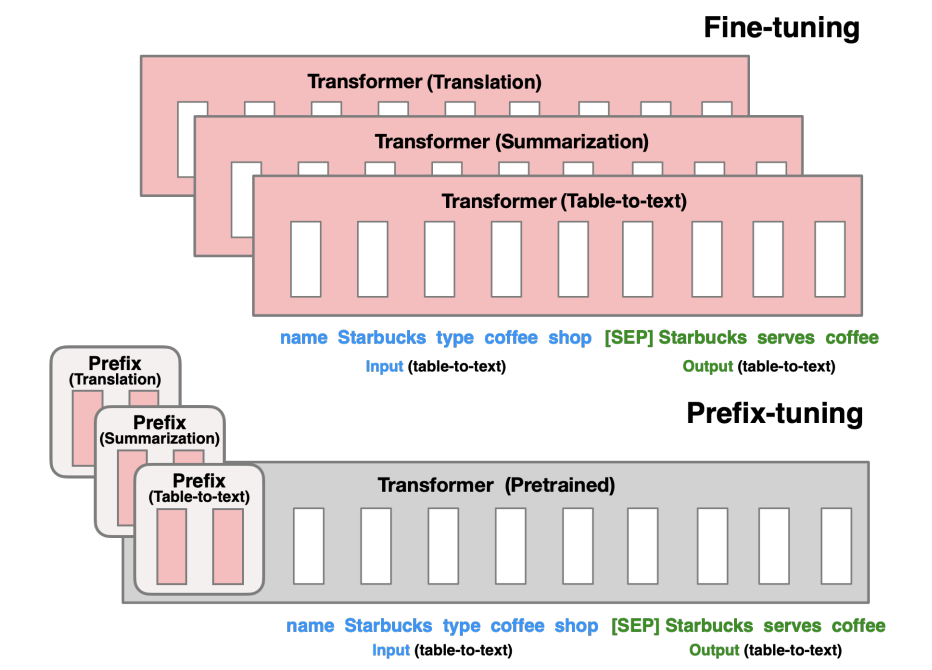
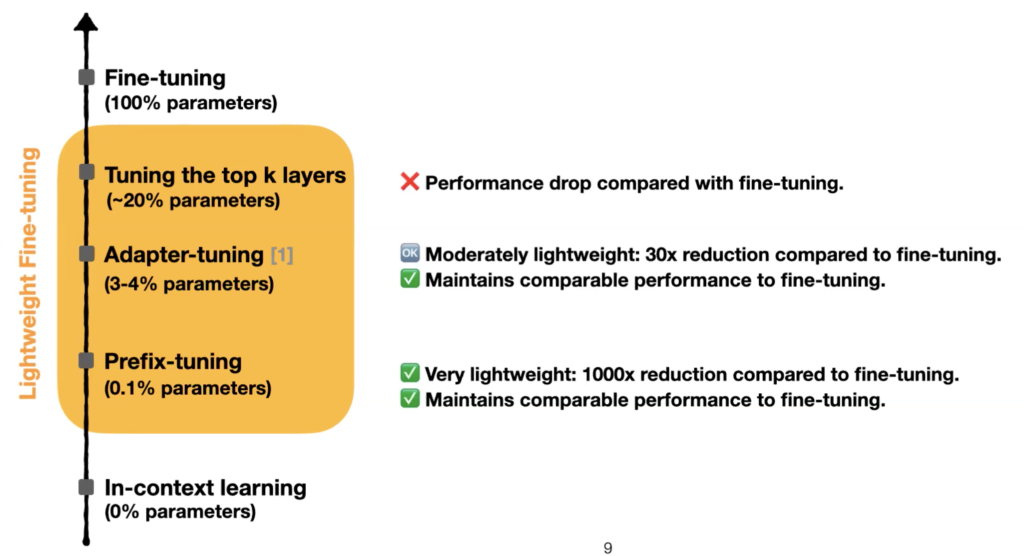
Fortunately, researchers have identified lightweight fine-tuning methods that reduce the number of parameters that must be updated when fine-tuning a model for a specific task. One such method is prefix tuning, proposed by Li and Liang (2021). Prefix tuning keeps the parameters of the pretrained model fixed, and only trains a small continuous “prefix” that is input to the model.
Specifically, prefix tuning prepends a learned continuous vector to the input. For example, in summarization, a prefix would be prepended to the input document. The prefix is tuned to steer the model to perform summarization while keeping the large pretrained model fixed. This is much more efficient, requiring tuning only 0.1% of the parameters compared to full fine-tuning.
Prefix tuning draws inspiration from prompting methods like in GPT-3, but optimizes a continuous prefix vector rather than using discrete tokens. The paper shows prefix tuning can match the performance of full fine-tuning on table-to-text and summarization tasks, while using 1000x fewer parameters per task.
In the sections that follow, we will explore how prefix tuning works, its advantages, experimental results, and comparisons to other efficient tuning methods.
Intuition Behind Prefix Tuning
The key motivation behind prefix tuning is that providing the right context or “prompt” to a language model can steer it to perform a downstream NLG task without needing to modify the model’s parameters.
Specifically, prefix tuning aims to learn a continuous prompt that can be optimized end-to-end, rather than relying on manual prompt engineering. When prepended to the input, the learned prefix provides the context needed to guide the model’s behavior towards the task objective.
By leveraging prompting while enabling end-to-end optimization of a continuous prompt, prefix tuning provides a way to adapt language models without extensive parameter tuning. The prefix allows injecting task-specific knowledge into the pretrained model in a lightweight way.
As an example, prepending relevant context like “Barack” can steer the model to generate “Obama” as the next word.
The goal is to find a prompt that can steer the model for generating entire sequences, not just single words.
Using natural language instructions as prompts (like “summarize this table”) doesn’t work well for current LMs. And finding specific tokens is challenging since optimizing over the choice of tokens is a discrete and combinatorial search problem.
Optimizinig the Instruction - Option 1: Optimize the discrete instruction via discrete optimization. Here you have to select w1 and w2 from the vocabulary such that prepending them would steer the generation of y conditioned on w1 w2 and x. However, discrete optimization is hard and we are constrained to choosing words from the vocabulary which is not very versatile.
Alternatively, you could optimize the instruction as continuous word embeddings. This is more expressive than discrete instructions and easier to compute because we now have a differentiable function but it is still constrained because we rely on the pre-trained parameters to compute the upper layers of the transformers.
Optimizing the Instruction - Option 2: Optimize the instruction as continuous word embeddings.
Instead, the authors propose optimizing a continuous prompt by tuning a prefix vector. This is easier and more expressive than using discrete words as prompts. (For this “continuous prompt” vector, you directly optimize over the vector values using gradient descent, which is a continuous optimization.)
Optimizing the Instruction - Option 3: Optimize the instruction as prefix activations of all layers.
Furthermore, by optimizing all layers of the prefix, the prefix is able to influence all model activations.
This is less expressive than tuning all model parameters (fine-tuning), but more lightweight.
How Prefix Tuning Works
The key idea behind prefix tuning is prepending a learned continuous vector, called the prefix, to the input of a pretrained model like GPT-2.
For example, consider a table-to-text task. The input x is a linearized table, and the output y is a text description.
Prefix tuning concatenates x and y into a single sequence z = [x; y]. (The authors do this concatenation step to create an “encoder-like” functionality since in GPT2 there is no explicit encoder. Thus, concatenating x and y allows the model to attend from y back to x, which is needed for conditional generation tasks where y depends on x. By concatenating x and y into one sequence z, the model can attend bidirectionally between x and y through the self-attention mechanism.)
Next, a prefix vector u is prepended to z to form the input [u; x; y]. This concatenated single sequence z is then fed into the Transformer model autoregressively. The model attends to previous tokens in z to predict the next token (i.e., computes hi as a function of zi and the past activations in its left context).
An annotated example of prefix-tuning using an autoregressive LM
The prefix u is a matrix with dimensions (prefix_length x d) where d is the hidden dimension size. For a prefix length of 10 and hidden size 1024, the prefix would contain 10,240 tunable parameters.
During training, the prefix values are optimized to maximize the likelihood of generating the correct output text y given input x. The gradients of the loss function are only computed with respect to the prefix parameters. The parameters of the pretrained model itself are kept completely fixed.
This training process tunes the prefix to assign high likelihood to the target descriptions y for each input x. Across many training pairs, the prefix learns to steer the model to perform the task-specific generation correctly.
This allows efficiently “steering” the model to generate outputs for the task, while avoiding any changes to the millions of parameters in the pretrained model. The prefix can be seen as injecting task-specific knowledge into the model.
The prefix tuning paper shows that this approach can match the performance of full fine-tuning on the E2E dataset using only 0.1% as many tuned parameters (250K vs 345M). The prefix provides a lightweight way to adapt the pretrained model.
Prefix Parameterization
Pθ is the full prefix matrix with size (prefix_len x d) where d is the hidden dimension.
The authors found that directly optimizing Pθ is unstable, so they reparameterized it with a smaller matrix P’θ.
They introduce P’θ, which is a smaller matrix with size (prefix_len x k) where k < d. So P’θ has fewer columns and is smaller than Pθ.
This reparameterization with the smaller P’θ acts as a “bottleneck” that helps stabilize optimization.
Then Pθ is computed from the smaller P’θ by: Pθ[i,:] = MLP(P’θ[i,:]). (MLP = a feedforward neural network.)
The MLP maps from the smaller P’θ to expand it to the larger full size Pθ.
After training, only the final Pθ is needed.
Benefits of Prefix Tuning
Prefix tuning provides several advantages over full fine-tuning:
Memory efficient – Only the small prefix needs to be stored for each task, rather than a full copy of the pretrained model. This allows scaling to large numbers of tasks.
Faster training – Updating only the prefix parameters is much faster than full model fine-tuning. No gradient computation through the full pretrained model.
Modularity – The pretrained model stays fixed and does not need any modification. This enables flexibly combining prefixes and pretrained models.
Better generalization – Freezing the pretrained parameters may improve generalization to new datasets and topics, relying on the capabilities of the model rather than overfitting the parameters. For example, the prefix tuning paper shows it extrapolates better than full fine-tuning when trained only on news articles and tested on sports articles. The untouched pretrained model can better leverage its capabilities on this new domain.
Personalization – Prefixes can be learned independently per user for personalization. A single pretrained model can support personalized prefixes.
Interpretability – The compact prefix can provide more interpretability than large fine-tuned models. Easier to inspect what knowledge has been injected.
In summary, prefix tuning provides an efficient and modular approach to steering large pretrained LMs compared to full fine-tuning.
Comparison to Other Methods
Comparison to other methods (fine tuning, adapter tuning, etc.)
Prefix tuning is not the only approach to tuning pretrained LMs. How does it compare to other methods?
Top K Tuning – Requires tuning top k layers, ~20% of model parameters. This method suffers a performance drop compared to full finetuning.
Adapter Tuning – This method inserts small task-specific adapter modules between each layer of the pretrained model. Prefix tuning attains similar performance with far fewer parameters (0.1% vs 1-4% for adapter tuning).
Discrete Prompting & In-Context Learning – Unlike manually designed prompts, prefix tuning optimizes a continuous prompt end-to-end. More expressive prompting.
So in summary, prefix tuning provides greater efficiency than adapter methods, avoids any pretrained weight changes, and benefits from end-to-end optimization of continuous prompts.
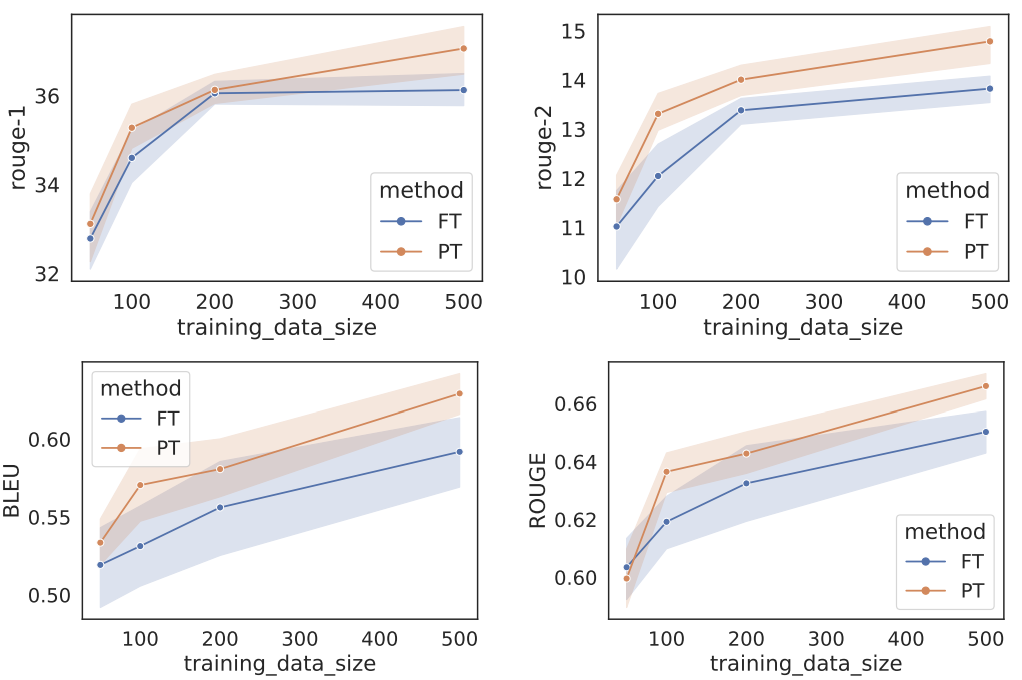
The figure below displays the results of prefix tuning compared to full fine tuning.
“...prefix-tuning (orange) outperforms fine-tuning (blue) in low-data regimes in addition to requiring many fewer parameters. The top two plots correspond to summarization, measured by ROUGE-1 and ROUGE-2. The bottom two plots correspond to table-to-text, measured by BLEU and ROUGE-L. The x-axis is the training size and the y-axis is the evaluation metric (higher is better).”
Conclusion
Prefix tuning provides an efficient alternative to full fine-tuning for adapting pretrained models to natural language generation tasks. By optimizing just a small continuous prefix, it can match the performance of full fine-tuning while using 1000x fewer task-specific parameters.
Key advantages of prefix tuning include efficiency, modularity, better generalization, and interpretability. It outperforms prior lightweight tuning approaches based on adapter modules.
Open questions remain around how well prefix tuning scales to even larger pretrained models like GPT-3, and whether techniques like prompt learning could be combined with prefix tuning. However, prefix tuning provides a promising step toward efficient and scalable adoption of large pretrained models.
By keeping the pretrained model fixed and injecting task knowledge into a small tunable prefix, prefix tuning points toward more modular and lightweight approaches to tuning foundation models. This will enable the scalable use of powerful pretrained models across many downstream applications.