
Introduction
ChatGPT-like models showcase the power of large language models for conversational AI. However, training such powerful models requires massive computational resources, making them inaccessible to many researchers and developers.
Microsoft’s newly open-sourced DeepSpeed-Chat aims to change that by providing an end-to-end framework for training ChatGPT-style models efficiently at any scale. DeepSpeed-Chat allows training models with hundreds of billions of parameters in record time using only commodity GPUs.
This is made possible by DeepSpeed-Chat’s optimized DeepSpeed-RLHF training system. It combines innovations in memory optimization, parallelism, and other techniques to achieve unparalleled efficiency and scalability.
In this blog post, we will provide an overview of DeepSpeed-Chat’s key capabilities and how it enables fast, affordable training of ChatGPT-like models to democratize conversational AI.
Key Capabilities
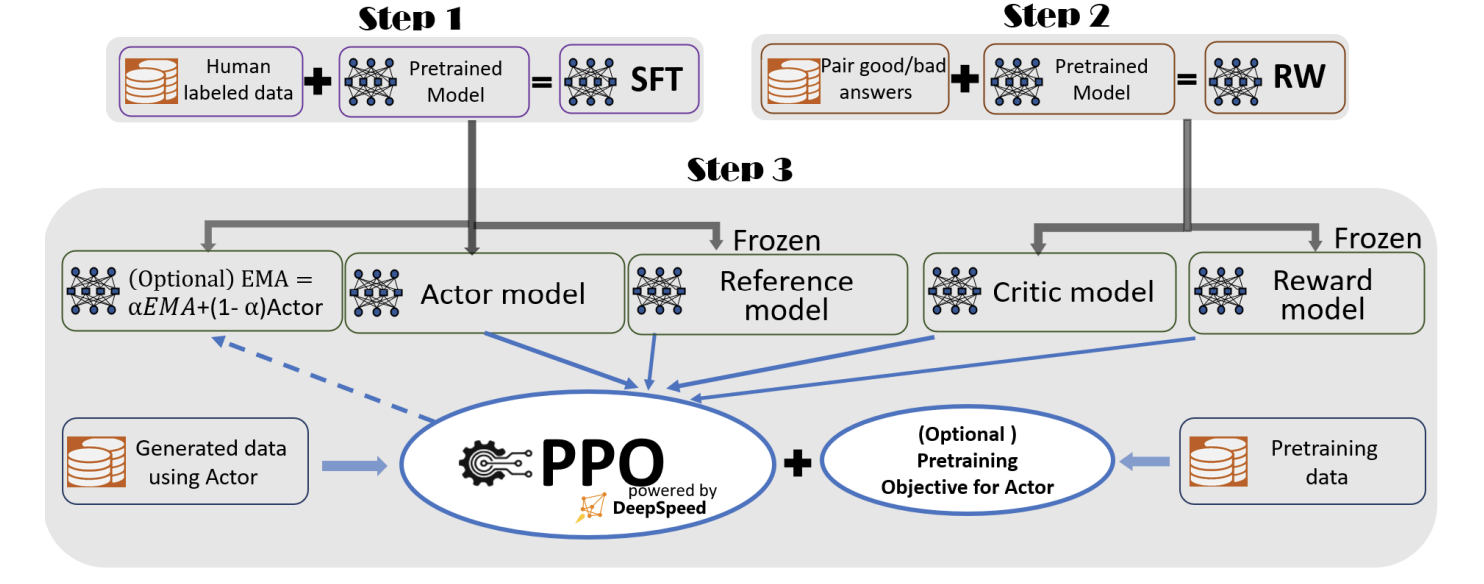
DeepSpeed-Chat provides an easy-to-use training and inference experience for creating ChatGPT-style models. With just a single Python script, users can train models ranging from 350 million to 175 billion parameters end-to-end. This includes supervised finetuning on a dataset of human responses, training a reward model to judge responses, and reinforcement learning with human feedback.
For example, this simple script can run a full RLHF pipeline comprised of finetuning a pre-trained OPT-13B actor model, using OPT-350M reward model in half a day:
pip install deepspeed >=0.9.0
git clone https://github.com/microsoft/DeepSpeedExamples.git
cd DeepSpeedExamples/applications/Deepspeed-Chat/
pip install requirements.txt
python train.py --actor-model facebook/opt-13b --reward-model facebook/opt-350m -deployment-type single_node
If you want to try different model sizes and configurations, it’s as easy as switching out the model size and switching the deployment-type parameter form single_node to multi_node. You can also run on consumer-grade gpu’s by switching the deployment-type to single_gpu.
After training, DeepSpeed-Chat provides an inference API to interact with the model conversationally and test its capabilities.
Under the hood, DeepSpeed-Chat implements the full RLHF training methodology pioneered in the InstructGPT paper. This includes the three key steps of supervised finetuning, reward model finetuning, and RLHF training. DeepSpeed-Chat also provides additional useful features like exponential moving average (EMA) collection (allowing the use of an EMA based checkpoint for the final evaluation) and mixture training (mixing the pretraining objective with the RLHF proximal policy optimization objective) to maintain strong performance on NLP benchmarks.
Powering this training pipeline is an efficient DeepSpeed-RLHF training system. It unifies optimizations from DeepSpeed’s inference and training engines to maximize throughput. This allows DeepSpeed-Chat to achieve up to 15x higher throughput than alternative frameworks like Colossal-AI or HuggingFace (which use native PyTorch). As a result, DeepSpeed-Chat can train models affordably even on the cloud – for example, a 13 billion parameter model can be trained for just $290 on Azure. (Note: please see the paper for more detail on cost.)
Technical Innovations
The key to DeepSpeed-Chat’s unparalleled efficiency lies in its Hybrid Engine. This engine seamlessly combines optimizations from both DeepSpeed’s training and inference systems to maximize performance throughout the entire RLHF pipeline.
During the inference generation phase, where the model must generate many candidate responses to each prompt, the Hybrid Engine relies heavily on tensor parallelism. By splitting the model across GPUs, tensor parallelism allows for fast parallel inference generation. This removes inference throughput as a bottleneck. If inference is run on a single GPU, the Hybrid Engine utilizes high-performance transformer kernels to maximize memory bandwidth utilization. In addition, to help boost inference performance, Hybrid Engine also uses a lightweight memory management system to handle KV-cache and intermediate results during inference.
In contrast, during the actual RL training phase, the Hybrid Engine switches to using ZeRO memory optimization. ZeRO allows the model’s parameters and gradients to be divided into smaller chunks and distributed across GPUs. This reduces the memory footprint for large models, enabling much bigger batch sizes.
Additionally, Microsoft’s Low-Rank Adaptation of Large Language Models (LoRA) technique is used here to “compress” and sparsify the model (LoRA reduces trainable parameters by freezing pretrained weights and injecting low-rank trainable matrices into each transformer layer), further decreasing memory consumption.
Beyond memory optimizations, the Hybrid Engine also utilizes DeepSpeed’s custom high-performance transformer kernels and optimized data movement.
This fluid combination of the right optimizations for each phase is what enables DeepSpeed-Chat to maximize efficiency throughout the entire RLHF pipeline. The result is a system that can achieve affordable RLHF and over 15x higher throughput on billion parameter models compared to alternate solutions as shown in the table and figure below.

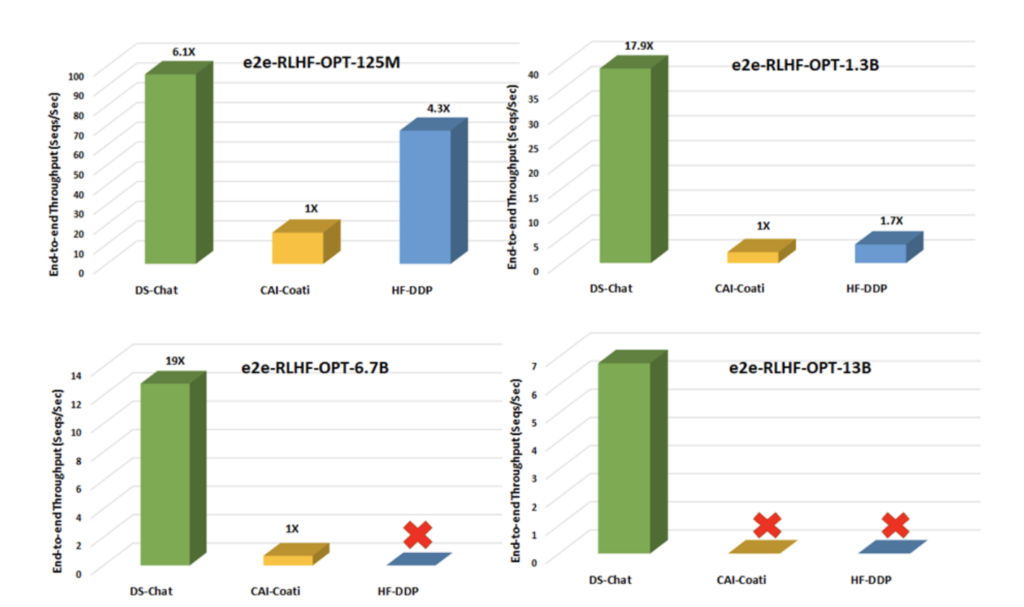
In summary, DeepSpeed-Chat’s Hybrid Engine uniquely fuses advances in inference generation, memory optimization, and data movement to overcome all training bottlenecks. This technical innovation is the key driver of the framework’s state-of-the-art efficiency.
Scalability
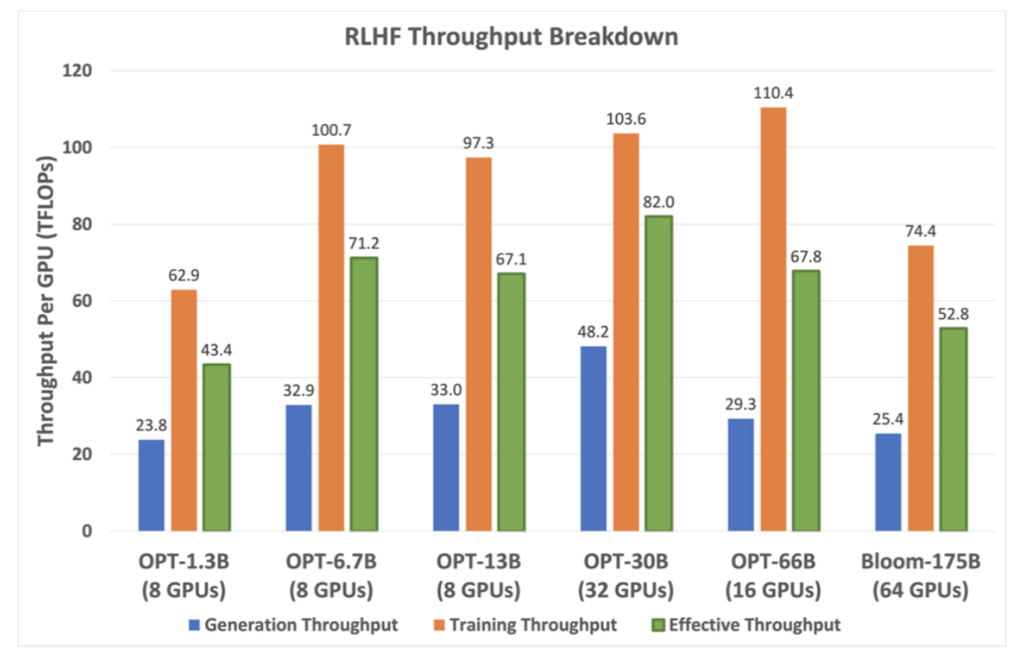
One of the most impressive aspects of DeepSpeed-Chat is its ability to scale training to models with hundreds of billions of parameters. This is enabled by the memory savings and parallelism techniques discussed earlier.
Key scalability results include (and highlighted in the table below):
- 175B parameter model trained in under 1 day
- 13B model trained in just 1.25 hours using 64 GPUs
- 10x lower cost than alternate solutions

This level of scalability significantly reduces the obstacles to training large conversational models, allowing for continual exploration of even bigger model sizes for RLHF.
The Hybrid Engine’s efficiency optimizations are key to these gains. The figure below shows the engine’s throughput advantage:
Customization
While DeepSpeed-Chat provides an end-to-end RLHF pipeline out-of-the-box, it also enables extensive customization for research purposes.
Users can leverage DeepSpeed-Chat’s flexible RLHF APIs to build entirely new training strategies:
engine = DeepSpeedRLHFEngine(
actor_model_name_or_path=args.actor_model_name_or_path,
critic_model_name_or_path=args.critic_model_name_or_path,
tokenizer=tokenizer,
num_total_iters=num_total_iters,
args=args
)
trainer = DeepSpeedPPOTrainer(engine=enginer, argos=args)
for prompt_batch in prompt_train_dataloader:
out = trainer.generate_experience(prompt_batch)
actor_loss, critic_loss = trainer.train_rlhf(out)
The key classes exposed include:
- DeepSpeedRLHFEngine: Manages models, optimizers, and training.
- DeepSpeedPPOTrainer: Implements PPO algorithm. Can be subclassed.
The modular API also facilitates evaluating different reward models, tokenizations, and more.
By providing these building blocks, DeepSpeed-Chat supports customizable R&D while handling most training optimization challenges under the hood. This is a powerful combination for conversational AI researchers.
Conclusion
DeepSpeed-Chat represents an exciting advancement in democratizing access to powerful conversational AI models. By optimizing end-to-end RLHF training, it enables fast, affordable model development.
Key highlights include:
- Easy setup with a unified training script
- Reproduces the full InstructGPT methodology
- Innovative Hybrid Engine for maximized efficiency
- Unparalleled scalability to 100Bs of parameters
- Democratization by making RLHF accessible to all
While conversational models like ChatGPT have great potential, equal access to the technology required to build them enables more stakeholders to shape the development of AI.
By open-sourcing an optimized RLHF framework, DeepSpeed-Chat lowers the barriers for entry and empowers more equitable advancement of conversational AI research.
The road ahead will involve even larger and more capable models. DeepSpeed-Chat provides a scalable foundation for this journey towards safer, more beneficial language AI.
References
